A technical deep-dive into designing a distributed, parameter-aware rate limiting SDK that handles multi-tenant workloads with heterogeneous payload contracts.
- The Problem: Rate Limiting by Request Payload, Not Just Endpoints
- Design Constraints and Trade-offs
- High-Level Architecture
- Configuration Design
- Distributed Counter Implementation with Hosted Redis
- Atomic Enforcement with Lua Scripts
- Operational Concerns: Graceful Degradation
- Lessons from an Unshipped Project
- Summary
- When to Build This
- Implementation Approach
The Problem: Rate Limiting by Request Payload, Not Just Endpoints
At Sprinklr’s AI team, multiple product subteams were building ML services, each with different rate limiting requirements. Some needed to throttle by document_id in the request body, others by tenant_id and language in headers, and some by model_version in query parameters. Traditional API gateways could only rate limit by IP address or API key—useless for these use cases.
This created two problems:
Insufficient granularity: A single API key might serve multiple tenants or workloads. Rate limiting the key itself was too coarse-grained—it would block legitimate traffic from one tenant when another tenant exceeded their quota.
Fragmented implementations: Without a shared solution, each product team was building their own rate limiting logic. This led to duplicated code, inconsistent enforcement semantics, and no way to share improvements across teams.
Existing solutions fell short. Netflix’s Zuul and Adobe’s multi-tenant throttling systems both implement parameter-aware rate limiting with distributed counters, but they’re tightly coupled to their respective infrastructures. No generic, reusable SDK existed that could be integrated into arbitrary services with minimal configuration.
As part of the AI Platform team, I designed and prototyped a rate limiter SDK to solve this problem for the product teams. The SDK is an embeddable library that handles distributed counter management, atomic operations, and hot-reloadable configuration, while letting each team define custom key extraction logic based on their request payloads (body, headers, query parameters). The project didn’t ship—priorities shifted toward copilot and agentic systems—but the design holds up, and the patterns are worth documenting.
Design Constraints and Trade-offs
Three constraints shaped the design:
Heterogeneous services: Each team’s service had different payload schemas and rate limiting needs. The NLP service cared about document IDs, while the sentiment service cared about tenant-language pairs. A one-size-fits-all gateway wouldn’t work.
No single point of failure: A centralized rate limiting service would become a bottleneck. If it went down, all services would be affected.
Configuration agility: Rate limits needed to change without redeploying services. Customer contracts and usage patterns evolved frequently.
This led to an SDK-based architecture rather than a gateway. Each team embeds the SDK in their own mediator service, maintains control over their deployment, and defines custom key extraction logic. The SDK handles the complex parts—connection pooling to the hosted Redis cluster, Lua script execution, atomic multi-tier checks, and TTL management.
Trade-offs of SDK vs Gateway Approach
| Feature | API Gateway (Kong/Nginx) | Cloud Provider (AWS/GCP) | SDK-based |
|---|---|---|---|
| Rate limit by custom payload field | ❌ | ❌ | ✅ |
| Embeddable in existing services | ❌ | ❌ | ✅ |
| Hot-reload config without deploy | ❌ | ⚠️ Limited | ✅ |
| Multi-tier rate limits (rps/rpm/rph/rpd) | ⚠️ Limited | ⚠️ Limited | ✅ |
| Centralized management | ✅ | ✅ | ❌ |
| Additional code in each service | ❌ | ❌ | ✅ |
The SDK approach trades centralized management for flexibility and resilience. Each service carries slightly more code, but gains independence and fine-grained control.
High-Level Architecture
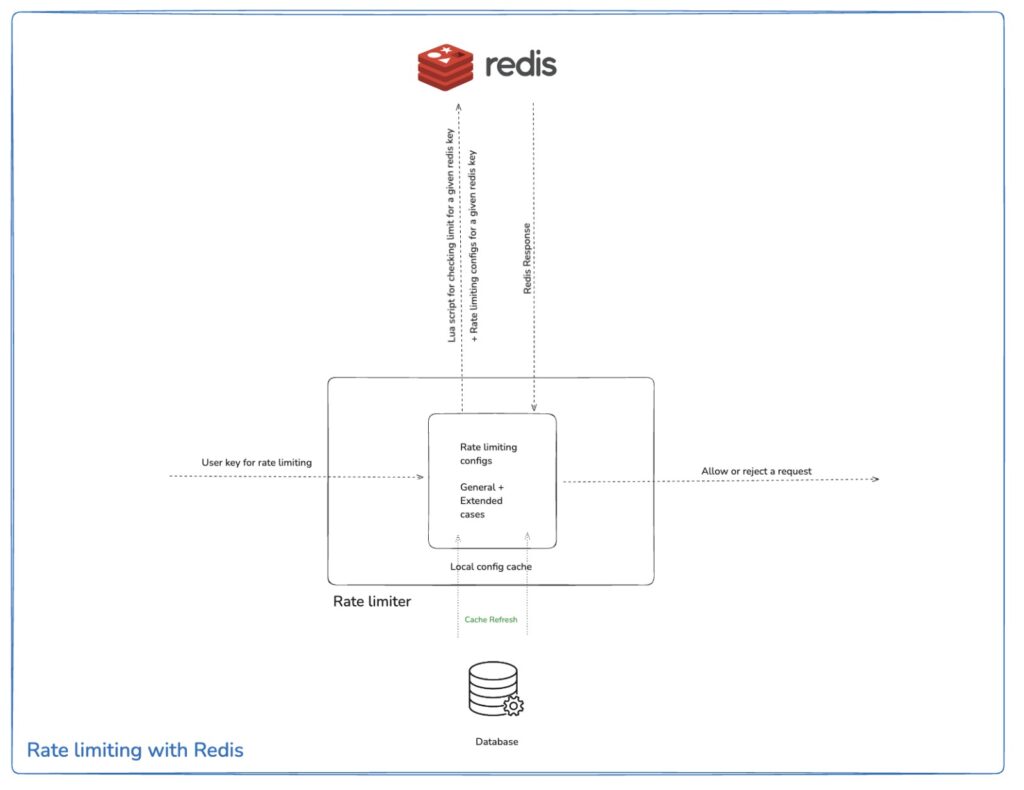
The architecture has three components:
Dynamic configuration store (MongoDB): Stores rate limiting rules per service. Configurations are cached in memory by the SDK and refreshed periodically (configurable interval, typically [30-60 seconds]), enabling updates without redeployment.
Distributed counter (hosted Redis cluster): The SDK calls a centrally hosted Redis instance that maintains request counts across all service instances. Each rate limit (rps, rpm, rph, rpd) gets its own key with an appropriate TTL. All service instances share this Redis cluster for counter synchronization.
Atomic enforcement (Lua scripts in Redis): All rate limit checks and decrements happen in a single atomic operation, preventing race conditions.
Request Flow
[Incoming Request]
↓
[Team's Mediator Service] ← (Team owns this)
↓
[Custom Key Parser] ← (Team implements this)
↓
[Rate Limiter SDK]
├─→ [MongoDB Config Cache]
└─→ [Redis + Lua Script] ← (Atomic multi-tier checks)
↓
[Allow/429 Response]
↓
[Application Service]
The SDK handles connection pooling to the hosted Redis cluster, Lua script execution, multi-tier enforcement, TTL management, and graceful degradation when Redis is unavailable. Teams implement custom key extraction logic based on their payload schemas.
This design decouples rate limiting logic from individual services while avoiding a centralized bottleneck. Each team’s mediator service runs independently, but all share a common hosted Redis cluster for distributed counter synchronization.
Configuration Design
MongoDB Schema
Each Kubernetes service manages its own rate limits, isolated from others. The configuration schema has two main sections:
general_rate_limit: Default limits applied to all requests not matching a custom rulecustom_rate_limits: Fine-grained limits indexed by custom keys, enabling targeted throttling by user, API, or parameter
Example configuration document:
{
"_id": "service-unique-id",
"last_updated": "2025-10-10T14:23:00Z",
"general_rate_limit": {
"rps": 20,
"rpm": 1000,
"rph": 50000,
"rpd": 100000
},
"custom_rate_limits": {
"user:1234": {
"rps": 10,
"rpm": 500,
"rpd": 50000
},
"apiKey:premium-tier": {
"rps": 100,
"rpm": 5000,
"rpd": 500000
},
"tenant:client-corp:lang:en": {
"rpm": 500,
"rph": 20000,
"rpd": 250000
}
}
}
Each service defines its own defaults and custom rules. Rate limiting rules for one service never interfere with another.
SDK Configuration Workflow
Fetch and cache: On startup, the SDK fetches the service’s configuration from MongoDB and caches it in local memory, avoiding a database roundtrip for every request.
Generate a key: Each team implements a custom key parser function that inspects the incoming request (headers, body, etc.) and constructs a unique key.
Find the rule: The SDK looks for an exact match for the generated key within
custom_rate_limits. If found, that specific limit is used. Otherwise, it falls back togeneral_rate_limit.Call hosted Redis: The SDK executes the Lua script atomically against the hosted Redis cluster to check all configured rate limits (rps, rpm, rph, rpd) and decrement them if allowed.
Cache Refresh Without Restarts
The SDK polls MongoDB periodically (configurable interval, typically [30-60s]) to check if its configuration has been modified (via last_updated timestamp). If changed, the SDK refreshes its in-memory cache. Other services’ SDK instances are unaffected—they don’t query MongoDB during this update.
Benefits:
- Updating rate limits for one service has zero impact on others
- Changes propagate within seconds, without redeployments
- No thundering herd—each SDK instance refreshes independently
Custom Key Extraction
Each service defines its own key extraction logic. The SDK provides a simple interface: implement a function that takes a request and returns a string key.
Example for sentiment analysis service:
# sentiment_service/rate_limit_parser.py
def extract_rate_limit_key(request):
"""
Custom key parser for sentiment analysis service.
We want to rate limit by: tenant_id + language combination
"""
headers = request.headers
body = request.json
# Option 1: Check for premium API key in header
if 'X-API-Key' in headers:
api_key = headers['X-API-Key']
if is_premium_tier(api_key): # Premium users get different limits
return f"apiKey:{api_key}"
# Option 2: Check request body for tenant + language
if 'tenant_id' in body and 'language' in body:
tenant = body['tenant_id']
lang = body['language']
return f"tenant:{tenant}:lang:{lang}"
# Option 3: Fallback to user_id if available
if 'user_id' in headers:
return f"user:{headers['user_id']}"
# Option 4: Ultimate fallback - IP address
return f"ip:{request.remote_addr}"
Different services have different extraction rules. For example, an image recognition service might extract keys differently:
# image_recognition_service/rate_limit_parser.py
def extract_rate_limit_key(request):
"""Rate limit by model version + resolution tier"""
body = request.json
model = body.get('model_version', 'v1')
resolution = 'hd' if body.get('hd_mode', False) else 'sd'
return f"model:{model}:res:{resolution}"
Complete Workflow
- Request arrives at team’s mediator service
- Mediator calls custom
extract_rate_limit_key()function - Generated key:
"tenant:client-corp:lang:en" - Mediator calls SDK:
sdk.check_rate_limit(service_name, generated_key) - SDK checks MongoDB config cache for
custom_rate_limits["tenant:client-corp:lang:en"] - If found, use those limits; otherwise, use
general_rate_limit - SDK builds Redis keys:
sentiment-service.tenant:client-corp:lang:en.rpm,.rpd, etc. - SDK executes Lua script to atomically check/decrement all rate limits
This design lets teams define complex rate limiting rules without modifying the SDK.
Distributed Counter Implementation with Hosted Redis
When running multiple service instances (pods) in Kubernetes, local in-memory counters don’t work—each pod only sees its own requests. A shared, centrally hosted Redis cluster provides distributed counter synchronization across all service instances with fast, atomic operations and built-in TTL support.
Fixed Window Algorithm
The implementation uses a fixed window strategy. Within each fixed-duration window (e.g., one minute), the system tracks request counts. Each request decrements the counter. When the window expires, the counter resets.
Trade-off: Burst traffic at window boundaries
Fixed windows have a known limitation. Consider a 1000 rpm limit:
00:00:59→ User sends 1000 requests (allowed)00:01:00→ Window resets00:01:00→ User sends another 1000 requests (allowed)- Result: 2000 requests in 2 seconds
A user can send one batch at the end of window N and another at the start of window N+1, temporarily exceeding quotas. For critical endpoints where this matters, sliding window or token bucket algorithms are more appropriate. Fixed window was chosen here for simplicity and performance—Redis operations are minimal (GET, DECR, SET with TTL).
Redis Key Naming
Consistent key naming in Redis is crucial for debugging and scaling. The key format is:
<service_name>.<user_key>.<granularity>Where:
service_name: Identifies which service is being rate limiteduser_key: The dynamic identifier generated per user/requester (API key, IP address, etc.)granularity: Time window (rps, rpm, rph, or rpd)
Example Redis keys during operation:
# Premium API customer - both time windows active
ml-service.apiKey:premium-client-xyz.rpm
→ Value: 847 TTL: 42s (started at 1000 rpm)
ml-service.apiKey:premium-client-xyz.rpd
→ Value: 8234 TTL: 16h 23m (started at 50000 rpd)
# Tenant-specific rate limit for non-English requests
sentiment-service.tenant:nike:lang:ja.rpm
→ Value: 12 TTL: 18s (started at 100 rpm)
sentiment-service.tenant:nike:lang:ja.rpd
→ Value: 1450 TTL: 9h 12m (started at 5000 rpd)
# Free tier user hitting general limits
image-service.user:john-doe-123.rpm
→ Value: 3 TTL: 51s (started at 50 rpm)
# Model-specific GPU quota limiting
inference-service.model:gpt-vision:res:hd.rpm
→ Value: 0 TTL: 8s (EXHAUSTED - returns 429)
Key lifecycle example:
- T=0s: First request from
user:alice→ Redis key created withvalue=999, TTL=60s - T=30s: [500 requests processed] →
value=499 - T=60s: TTL expires → Redis automatically deletes the key
- T=61s: New request arrives → Fresh key created,
value=999, TTL=60s
Redis’s TTL mechanism handles garbage collection automatically—no stale keys accumulate.
Implementation Details
On the first request for a unique key-granularity combination, a key is created in the hosted Redis cluster with the configured limit as its value and a TTL matching the window duration (e.g., 60 seconds for rpm). Subsequent requests decrement the counter. When the TTL expires, Redis automatically cleans up the key.
This provides a global rate limiter that works across all service instances by leveraging the shared, hosted Redis cluster.
Atomic Enforcement with Lua Scripts
Distributed rate limiting requires atomic check-and-decrement operations. Without atomicity, race conditions occur.
The Race Condition Problem
Consider an rpm counter with one request remaining:
- Request A reads the counter:
value = 1(allowed) - Request B reads the counter simultaneously:
value = 1(allowed) - Request A decrements:
value = 0 - Request B decrements:
value = -1
Both requests were allowed, despite only one slot being available. Separate read and write operations create a race condition.
Atomic Operations with Lua
Lua scripts in Redis execute atomically—the entire script runs without interruption. The check-and-decrement logic becomes a single operation.
The script:
- Receives multiple Redis keys: e.g.,
["service.user.rps", "service.user.rpm", "service.user.rph", "service.user.rpd"] - Checks all counters first: If any counter is zero or negative, abort immediately
- Decrements all counters: Only if all checks passed
- Returns result:
{allowed: true/false, remaining: {rps: N, rpm: M, ...}}
Multi-tier enforcement is critical. A user might be within their daily limit but have exhausted their per-second quota—the request must be denied. All rate limits are checked atomically before any are decremented.
Pseudocode
function check_and_decrement_rate_limits(redis_keys, ttls, limits):
"""
Args:
redis_keys: ["service.user123.rps", "service.user123.rpm", "service.user123.rph", "service.user123.rpd"]
ttls: [1, 60, 3600, 86400] // seconds for each granularity
limits: [20, 1000, 50000, 100000] // initial limits for each granularity
Returns:
{allowed: boolean, remaining: {rps: N, rpm: M, ...}}
"""
allowed = true
remaining = {}
// PHASE 1: Check ALL rate limits first
for each redis_key in redis_keys:
current_value = REDIS.GET(redis_key)
if current_value does not exist:
// First request in this window - will initialize below
continue
if current_value <= 0:
// This rate limit is exhausted - REJECT immediately
allowed = false
break // Stop checking, request is denied
// PHASE 2: Only decrement if ALL checks passed
if allowed:
for each redis_key in redis_keys:
current_value = REDIS.GET(redis_key)
if current_value does not exist:
// First request: initialize counter with TTL
REDIS.SET(redis_key, limits[i] - 1, TTL=ttls[i])
remaining[redis_key] = limits[i] - 1
else:
// Decrement existing counter
new_value = REDIS.DECR(redis_key)
remaining[redis_key] = new_value
return {allowed, remaining}
Key properties:
- Atomicity: Redis guarantees the entire script runs without interruption
- Multi-tier enforcement: All rate limits (rps, rpm, rph, rpd) are checked. If any is exhausted, the request is denied
- Check-then-act: All limits are validated before any counters are modified
- Automatic cleanup: Redis’s TTL handles expiry—no manual garbage collection needed
Operational Concerns: Graceful Degradation
In distributed infrastructure, graceful degradation is as important as core functionality. The rate limiter should never block requests when its dependencies fail.
MongoDB Unavailable
If MongoDB is unavailable, the SDK continues using the most recently cached configuration. Rate limiting rules remain static until connectivity is restored.
Acceptable because:
- The cache is always present (loaded at SDK initialization)
- Rate limits continue to be enforced
- Only configuration updates are delayed
Hosted Redis Cluster Unavailable
If the hosted Redis cluster is unreachable, the SDK temporarily disables rate limiting (“fail-open”). All requests pass through unthrottled. This ensures the primary application functionality is never blocked by rate limiting infrastructure outages.
The SDK surfaces metrics/alerts when this happens so teams can respond quickly.
This approach prioritizes availability over strict enforcement. In rare outages of the hosted Redis cluster, protections drop, but legitimate user requests are never wrongly denied.
Lessons from an Unshipped Project
This project never reached production—priorities shifted toward copilot and agentic systems. However, the design process provided valuable lessons about distributed infrastructure.
Research Insights
Studying Netflix’s Zuul and Adobe’s multi-tenant throttling revealed a pattern: parameter-aware rate limiting is essential at scale, but most companies build custom solutions because off-the-shelf options are too rigid.
Key observations:
- Netflix’s Zuul: Uses servlet filters with distributed counters, but heavily customized for their infrastructure
- Adobe’s multi-tenancy: Built tenant-aware throttling into their API gateway, tightly coupled to their stack
- The gap: No generic, reusable SDK existed that could integrate with arbitrary services with minimal configuration
Applicability
This architecture is relevant for:
- Building parameter-aware rate limiters
- Handling multi-tenant workloads with heterogeneous services
- Evaluating distributed systems patterns for similar problems
- Considering trade-offs between centralized and decentralized approaches
The patterns are sound, and the trade-offs are well-reasoned. The implementation was validated in prototype form.
Summary
Key design decisions:
- Loose coupling: Dynamic configuration (MongoDB) enables updates without redeployment
- Atomic operations: Hosted Redis cluster with Lua scripts provides distributed counters and prevents race conditions under high concurrency
- Graceful degradation: The system prioritizes availability—rate limiting failures never block application requests
- Parameter-aware throttling: Teams define custom key extraction logic based on their domain needs
These patterns generalize beyond rate limiting to other distributed infrastructure problems.
When to Build This
A custom rate limiter is unnecessary if:
- Simple IP/API key limiting is sufficient
- Operating in a single-tenant environment
- Existing API gateway features meet requirements
Consider building if:
- Need parameter-aware throttling based on custom payload fields
- Have heterogeneous microservices with different rate limiting requirements
- Require multi-tier rate limits (rps, rpm, rph, rpd) enforced atomically
- Need hot-reloadable configuration without deployments
- At scale where race conditions matter
- Prefer decentralized ownership (SDK model) over centralized gateways
Implementation Approach
Starting points for a similar system:
- Lua script first: Atomic logic is the hardest component. Validate the approach early
- Minimal config schema: Start simple, add complexity incrementally
- Single-service integration: Prove the design in one service before generalizing
- Observability: Instrument everything—metrics, logging, and alerting are critical at this layer
- Failure mode testing: Validate behavior when dependencies (Redis, MongoDB) fail
If you have questions or want to discuss distributed systems architecture, feel fre to reach out:
- Email: sanjaysinghbudhala23@gmail.com
- LinkedIn: sanjaysingh